A Quick Introduction to Coding Your Own Retrieval Augmented Generation (RAG) System
This walkthrough is heavy on the Vercel - leveraging React, Next.js, Prisma, Vercel Postgres (with pgvector as the vector database), and TypeScript



Motivation
I have been researching Retrieval Augmented Generation for a while, learning where it is a good fit and what are the various tools that can be used. But I wanted to get a working RAG system of my own. I have been talking a bit about Legal AI tools, and that is where I will apply this technology eventually - but I wanted to start with something a little more fun: writing music!
In this walkthrough, I will take you through creating a RAG project based on Vercel's starter project for pgvector. My walkthrough will show you how to create your own embeddings, and then adds on the step of creating a fresh new song based on the most relevant passages. Buckle up!!
Here is an overview of the basic steps that we will walk through. We will start by populating our Background table with embeddings of awesome lyrics. Then, when a user wants to create their own song, they will enter a song idea and we will pull the 5 most relevant lyrics and instruct the LLM to generate a song based on what the user entered + the most relevant lyrics. Easy!

Deploy Vercel's pgvector project
Vercel has created a product that allows you to do half of RAG at https://vercel.com/templates/next.js/postgres-pgvector. Specifically, this project shows you an instance of using Postgres's pgvector (with a bunch of pre-seeded data) to determine the similarity of the user's submitted query to those (pre-seeded) entries. So it is more of a Retrieval project than a RAG project, but it will get you moving in the right direction.
As far as the functionality, each character that is typed into a search bar causes a new embedding to be looked up...which is kind of cool, but ends up tripping the throttling limits. If you visit Vercel's Demo Site at https://postgres-pgvector.vercel.app/, you will probably get a "No Results Found" - and some non-descriptive errors like "Failed to load resource." When you deploy this into your own account, you will see that this is tripping up throttling.
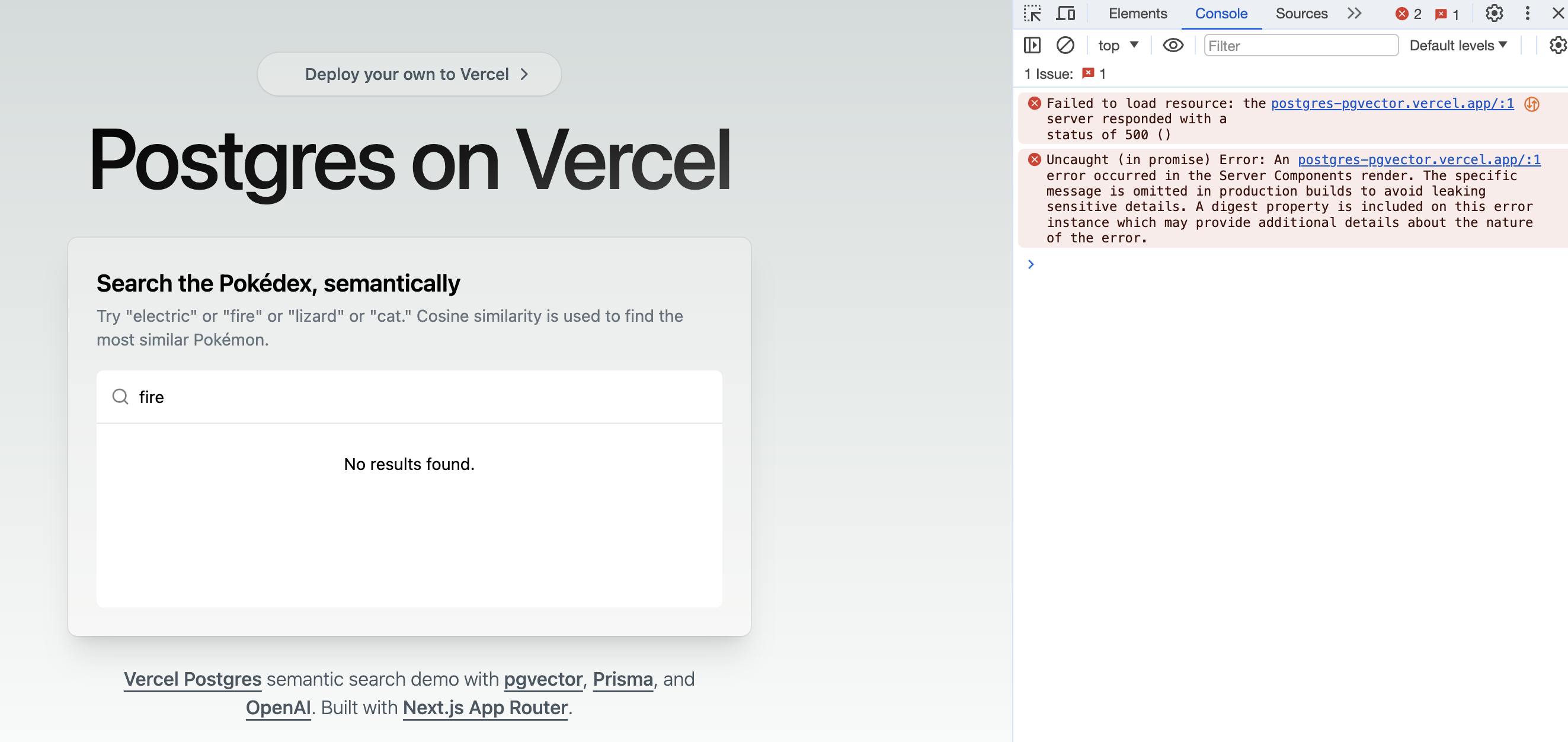
So first things first - add a (terribly designed) button and only submit the request to OpenAI when a user clicks on the button.
class AddEmbedding extends Component {
handleClick() {
toast.loading(`Our best minds are working on it!`)
backgroundText(query).then((results) => {
setBackgroundResults(results)
console.log('should see top 5 results')
console.log(results)
setQuery('')
})
}
render() {
return <button onClick={() => this.handleClick()}>Add Your Lyric</button>;
}
At this point, you may notice that I have converted from the Pokemon focus of Vercel's post to a "background" focus. Let me explain. The background table hosts the data that will queried and relevant content will be injected into the prompt. The foreground represents the prompts that a user intends to invoke (e.g., write a song of their own about)....but we will get to foreground later.
For creating the background embeddings, we will use the text-embedding-ada-002 in the actions.tsx file as shown in the code below
async function generateEmbedding(raw: string) {
// OpenAI recommends replacing newlines with spaces for best results
const input = raw.replace(/\n/g, ' ')
const embeddingData = await openai.embeddings.create({
model: 'text-embedding-ada-002',
input,
})
const [{ embedding }] = (embeddingData as any).data
return embedding
}
Then, we store the embedding + the original code in the database. Note that Prisma does not "support" embedding datatypes, so you need to use this type in your schema.prisma file.
model Background {
id String @id @default(cuid())
body String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
embedding Unsupported("vector(1536)")?
@@map("background")
}
Here is where it gets interesting: you cannot see this embedding field in Prisma Studio and you cannot interact with it via Prisma ORM. You could use something like pgAdmin to look directly at the database (to overcome the Prisma Studio limitation), or you could just pray.
To overcome the inability to interact with embedding fields in Prisma ORM is a bit more challenging. I think I came up with an acceptable approach to this, but let me know if you disagree. In short, I create the Background element using standard Prisma ORM, but then I update the Background record with the embedding value provided by OpenAI. This means that no user-keyed data is ever passed to the prisma.$executeRawUnsafe (this is marked as unsafe because it is subject to SQL injection). Here is the block of code from actions.tsx that handles the embeddings generation + the creation of the record + the addition of the embedding to the created record:
const embedding = await generateEmbedding(query)
// now we are going to insert
const vector_query = `[${embedding.join(',')}]`
//we are going to first insert the record using standard prisma,
//and then update with prisma.$executeRawUnsafe to avoid SQL Injection from
//end user submitted code.
const body = query
const created_background = await prisma.background.create({
data: {
body,
}
})
const background = await prisma.$executeRawUnsafe('UPDATE Background SET embedding=$1 WHERE id=$2;', embedding, created_background.id )
Now Let's RAG
To this point, we have focused on getting lyrics + embeddings into our background table. Now, it is time to leverage the most relevant lyrics and do some RAG!
We have built the "background" - now it is time to establish the "foreground" - what we want our song to be about. You can enter a word or a phrase or a lyric to describe your foreground. This foreground will be used to pull the relevant background and generate the song.
We already have background established, so now we need to do two things:
Pull background relevant to your foreground.
Submit a modified prompt to the LLM based on the foreground + the most relevant background.
This took a little experimentation, and this problem aint solved, but here is how I accomplished each of those steps:
async function generateCompletion(raw: string) {
const input = raw.replace(/\n/g, ' ')
//1. lookup 5 related
const embedding = await generateEmbedding(input)
const vectorQuery = `[${embedding.join(',')}]`
const background_array = await prisma.$queryRaw`
SELECT
id,
"body",
1 - (embedding <=> ${vectorQuery}::vector) as similarity
FROM background
where 1 - (embedding <=> ${vectorQuery}::vector) > .5
ORDER BY similarity DESC
LIMIT 5;`
const related_background_array = background_array as Array<Background>
//2. append them as user commands
const background_chat = " Yes. " + (related_background_array.map((background) => "I also want you to be inspired by the following lyrics if you can: " +background.body + ". "));
console.log(background_chat.toString())
const completionData = await openai.chat.completions.create({
model: 'gpt-3.5-turbo-1106',
messages:
[
{"role": "system", "content": "You are a song writing assistant."},
{"role": "user", "content": "Can you write me a quick song about " + input},
{"role": "assistant", "content": "I can write a song for that. Are there any lyrics you would like me to reference for inspiration?"},
{"role": "user", "content": background_chat.toString()},
{"role": "user", "content": "Please do not respond with anything but the song. "},
],
})
const song = completionData.choices[0].message.content + "\n\nThe following lyrics were added to the prompt " + related_background_array.map((background) => background.body)
return song
}
Note that the prompt took some massaging, as I initially said "write a song with these lyrics" and the safety filters kicked in and said no bueno when certain song lyrics were entered. OpenAI seems to be copasetic with using lyrics as inspiration.
Note: I instruct the LLM to {"role": "user", "content": "Please do not respond with anything but the song. "}, because it was adding an initial sentence like "Sure, I can help you write that song." Note how I am respectful to the LLM, because I do not know when the power is gonna flip.
Now Let's Use This RAG
There are 2 ways to interact with this system. First, you can add some background lyrics to the system: anytime that you are listening to a song, add your favorite lyric here: lyricmatch.dyor.com. This is just creating the background data, so it aint yet RAG.
When you wanna go full RAG, head on over to lyricmatch.dyor.com/prompt and enter something that you are truly passionate about: hobie cat'ing with dragons, espresso and cookies, your imagination is the limit. Whatever you enter will pull in a set of relevant lyrics, and a song will be created right before your eyes. If you scroll down to the bottom, you will see the lyrics that were RAG'ed into your song. Pretty cool.
Here is what you see if you enter "mexican beaches"

And if you scroll down to the bottom of the song, you see that the following lyrics were used as background for this song:
Step from the road to the sea to the sky,
Nightmare dressed like a daydream,
monday, tuesday, wednesday, thursday, (<--not really sure why this was included:)
All i gotta say is they don't really care about us,
All I wanna do is have some fun. I got a feeling, that I'm not the only one
Get this Code
I currently have marked this repo as private, because I think I will be radically improving it in the near future. But, if you are looking for some raw bits and roll your own RAG, send me a message at linkedin.dyor.com and I will either grant you access or make it public.
Appreciation
Thanks to ideogram.ai for the cover image. If you have not tried ideogram.ai, you should!
Thanks to GitHub Codespaces for allowing me to code on a borked laptop. If you have not tried Codespaces, you should!
Thanks to Vercel for creating every(infra)thing that a startup needs to get up and running. You do great things!
Thanks to everybody who likes, shares, sends me a message telling me something is borked, or sends me a message saying gracias.